Implementing a Scalable Judging System
I’ve written about good competition judging methods before. It’s hard to do well, but it can be done.
It turns out that it’s hard to scale.
Given that the algorithm used at Blueprint worked pretty well, naturally, I wanted to use the same general method for HackMIT. However, the requirements for a 1000-person event are pretty different from a 200-person event.
The old algorithm does not scale: by a rough estimate, it would take roughly 3 years to solve a 300 team case of the convex optimization problem. Our Matlab implementation, which used CVX with the SDPT3 solver, seemed to be taking exponential time. It wasn’t clear how to optimize it — having the normal CDF inside the objective function makes things hard for numerical optimization.
Also, the logistics of dealing with over a thousand people are a lot more complicated than dealing with a couple hundred people.
A New System
When coming up with a new system, I wanted to preserve some nice properties of the original method. For the reasons outlined in my previous post, I wanted to stick to a method based on pairwise comparison. However, the new method would need to scale to hundreds of teams and hundreds of judges.
Method
We decided to separate general judging from sponsor prize judging.
For sponsor prizes, we set aside a separate time when teams could go directly to sponsors and pitch their projects. Sponsors would independently decide how to judge for their prizes.
For the main competition, with such a large number of entries, we decided to have a two phase judging process.
Phase 1: Expo Judging
In the first phase, we had a giant expo to decide the top 10.
100 judges. 1000 participants. 90 minutes.
Everything here was managed by a computer, from real-time judge dispatch to rank computation. We used a system based on pairwise comparison, so judges would look at projects one after another, and for each project, decide if it was better or worse than the previously judged project.
Phase 2: Panel Judging
After expo judging, we had a panel of five judges look at the top 10 finalists. Each team delivered a 5-minute pitch and answered judges’ questions.
Choosing the 1st, 2nd, and 3rd place teams was left entirely up to our panel.
Algorithm
During expo judging, we used a pairwise comparison system. Because the old algorithm didn’t scale, we needed to find something else. After a lot of research, I decided to implement a system based on the Crowd-BT paper, which describes an algorithm based on the Bradley-Terry model of pairwise comparisons. Using this rather than the Thurstone model, which was used in the old system, allows for simpler and faster algorithms.
The Crowd-BT algorithm has a couple nice features. Instead of dispatching judges randomly, it assigns judges in such a way that maximizes expected information gain. It also allows updating rankings efficiently in an online manner, taking time to process single votes and taking time to tell a judge where to go next.
Implementation
The judging system was implemented as a web application. We added all the projects and judges to the system, and then we emailed the judges a magic link to get started.
The judges opened up the judging interface on their phone, and they were directed to their first project. After looking at that, they could start voting:
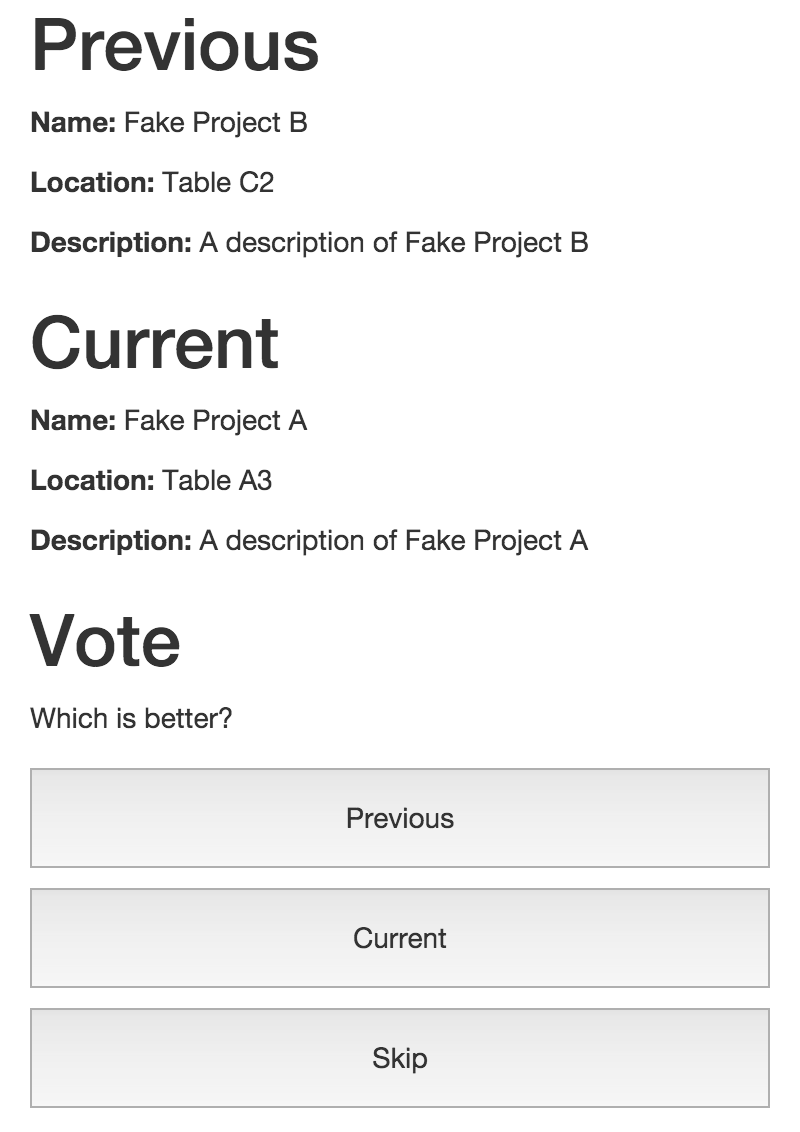
Judging logistics were completely handled by the system. The software told judges which projects to look at based on the algorithm, collected data, and computed results.
While judges were ranking projects, we could see all votes and rankings in real time in the admin dashboard.
Results
We were really happy with the way judging worked out at our event. During the expo, we had 1351 votes from 108 judges for 195 unique project submissions.
Here’s a visualization of the data that we collected. Nodes represent projects, and an edge from X to Y indicates a judge choosing Y over X.

Raw Data
We collected a lot of raw data from the pairwise comparisons, including things like which judge cast which vote, the time each vote was cast, and so on. We’re making it available in anonymized form in case anyone wants to do any analysis with our data.
Source Code
As of now, the code is fully functional, but the interface needs work. When I have some time, I’m planning on improving the software and then open-sourcing it.
Until that point, for early access, email me. A couple other hackathons have already used the software and have been quite happy with the results.
Update (9/19/2016): The judging system has finally been open sourced!